Search marketing can bring lots of benefits to your business and provide great marketing ROI. If you do it right, organic search provides you with a high-quality source of qualified traffic. However, SEO is much more than keywords and links. There are lots of technical aspects to SEO that, if you’re not careful, can trip you up and keep your site from performing as well as it could.
Here are five of the most common or trickiest to diagnose technical SEO mistakes you should avoid on your website.
Overzealous Robots.txt Files
Your robots.txt file is an important tool for your website’s SEO, and an integral part of making sure your website is properly crawled and indexed by Google. As we’ve explained in the past, there all sorts of reasons you wouldn’t want a page or folder to get indexed by search engines. However, errors in robots.txt files is one of the main culprits behind SEO problems.
A common technique to mitigate duplicate content issues when migrating a website, disallowing entire servers, will cause whole sites not to get indexed. So, if you’re seeing a migrated site failing to get traffic, check your robots.txt file right away. If it looks like this:
User-agent: *
Disallow: /
You’ve got an overzealous file that’s preventing all crawlers from accessing your site.
Fix this by getting more specific with the commands you issue in your file. Stick to specifying specific pages, folders or file types in the disallow lines like so:
User-agent: *
Disallow: /folder/copypage1.html
Disallow: /folder/duplicatepages/
Disallow: *.ppt$
Of course, if you created the original robots.txt file as part of your website migration, wait until you’re done before you start allowing bots to crawl your site.
Inadvertent NoIndex Tags
The meta robots tag goes hand-in-hand with the robots.txt file. In fact, it can be wise to double up by using the meta robots tag on a page you’ve disallowed via robots.txt. The reason is that robots.txt won’t stop search engines from accessing and crawling a page it finds by following a link from another site.
So it could still wind up indexing pages you don’t want crawled.
The solution to this is to add the meta robots noindex tag (also known just as the noindex tag) to pages you really, really don’t want indexed. It’s a simple tag that goes in a page’s <head>:
<meta name="robots” content=”noindex”>
Again, there are plenty of times you’d want to use the meta robots tag to prevent a page from getting indexed. However, if your pages aren’t getting crawled (you can check this using the site: search operator in Google), this should be one of the first things you check.
If you’ve used the site: search operator to check the number of pages you have indexed and it’s way below the number of pages you actually have, it’s time to crawl your site. Use WooRank’s Site Crawl feature to crawl your pages. Then, click on Indexing. Pages that are disallowed via the meta robots tag will be listed here.
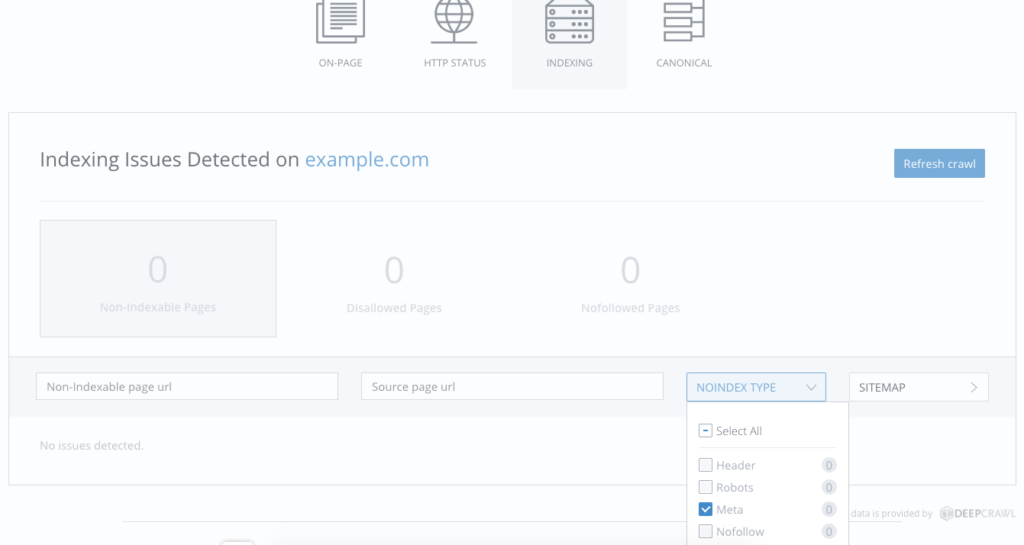
No problems with meta robots here. Nice.
Unoptimized Redirects
No matter how much you try to avoid using them, 301 redirects are sometimes necessary. 301s (and now 302s) enable you to move pages to new locations and still maintain link juice, authority and ranking power for those pages. However, 301s can only help your site’s SEO if you use them correctly. Implementing them incorrectly, or setting them and then forgetting about them completely, will deteriorate your user experience and search optimization.
There are four main ways unoptimized 301 redirects will hurt your SEO.
Redirect Chains
Let’s say you could have a page at www.example.com/search-engine-optimization that you decide to move to www.example.com/SEO. And then, a few months later, you decide to move it to www.example.com/marketing/SEO.
Now you’ve got a redirect chain on your hands.
A redirect chain occurs when a link points to a URL that redirects users to another URL that redirects users to a third (or fourth, or fifth, etc.) URL. They can occur when you’ve moved a page multiple times.
Even though all 3xx redirects pass full link equity, you still need to avoid piling redirects on top of each other because each one is going to add to your page load time. It may seem like quibbling to care so much about milliseconds, but when every tenth of a second can impact your conversions, it’s a quibble worth quibbling. And once you start stacking two or three redirects on top of each other, your users will be waiting an extra two or three seconds to get to the final page.
You, and Google, are going to see a high bounce rate.
Again, use a crawler here to find instances of redirect chains. The Screaming Frog SEO Spider has a nice report that will show you every redirect chain you link to. This report includes external redirect chains, which you don’t have any control over.
Redirecting Internal Links
Sometimes you just can’t stop a backlink from pointing at a redirected URL. However, there’s no reason for the links under your control, your internal links, to point at 3xx redirects. These redirects add unnecessary load times to your pages.
To find your redirected internal links head to Google Search Console and download your internal links under Search Traffic.
Use the concatenate function in Excel to insert your domain in front of the URL. Then, copy and paste those URLs into your crawler to return your internal links that return a 3xx status. This will give you a nice list of every redirected internal link you have on your site.
The process of fixing these links is as simple as updating the destination URL to the new URL.
Redirected Canonical URLs
As the name would suggest, canonical URLs are, well, the right URL according to your website’s canon. They are your “true” URLs. So it stands to reason that the URLs listed in your site’s canonical tags should never point to a redirect.
Search engines will follow the link in a canonical tag and pass the page’s ranking attributes there. So, functionally, adding a 301 to that process is like creating a redirect chain; the crawler now has to go through two steps to get to the destination.
Crawl your site to compile your list of URLs used in canonical tags, and then crawl that list of URLs to find the ones returning a 3xx status. Update either your canonical tags (or server, depending on which is the issue) to point canonical links at non-redirecting URLs.
Mismatching Canonical URLs
Along with redirecting canonical URLs, having conflicting canonical URLs is another tricky technical SEO mistake that could be holding back your pages. Conflicting canonicals, or canonical mismatches, occur when the URL used in a page’s canonical tag doesn’t match other places you should be using your canonical URL.
The two most common instances of this include:
- Sitemap mismatch: This error occurs when the link in the canonical tag doesn’t match the URL listed in your sitemap.
- Relative links: Search engines only recognize full URLs in canonical tag, so using just a file, folder or path here isn’t going to do anything for you.
Canonical tags are an important tool in the fight against duplicate content and sending link juice to the right pages. Using mismatch URLs here is going to undermine that whole strategy, causing search engines to see lots of duplicate pages (relative to the size of your site, of course) and for large reservoirs of link equity to form, benefiting only one page on your site.
Hreflang Return Tag Errors
The hreflang tag is used to point search engines and other web crawlers to alternate versions of a particular page in other languages. It can also specify that a page is meant for users in a certain country. If you’ve got an international and/or multilingual website, you’ve got hreflang tags on your pages (and if you don’t, you really should).
One technical mistake that’s easy to make with hreflang errors is what’s known as the “return tag error.” This error occurs when page A references page B in an hreflang tab, but page B doesn’t have a corresponding tag for page A. So, for page A, you’d have:
<link rel="alternate” hreflang=”en” href=”https://www.example.com/page-A”>
<link rel="alternate” hreflang=”es” href=”https://www.example.com/page-B”>
While page B would just have:
<link rel="alternate” hreflang=”es” href=”https://www.example.com/page-B”>
Every version of a page must reference every other version for hreflang to work properly. Make sure to note that pages have to reference themselves also. Missing the self-referencing tag is probably the most likely cause of hreflang return tag errors.
You can find hreflang tags that have return tag errors in Google Search Console in the International Targeting report under Search Traffic.

If you’ve used WooRank’s Site Crawl to find any of the other errors above, you’ll also find return tag errors and other mistakes with hreflang in the Canonical section.
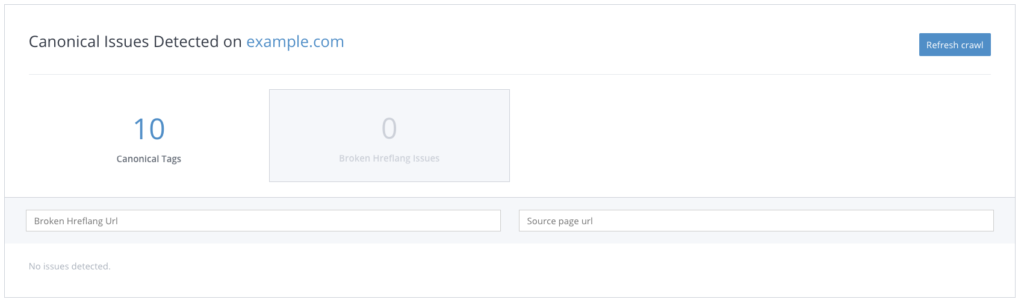
Again, no errors here. Nice.
Wrapping It Up
Dodging these five technical SEO mistakes won’t automatically put your website at the top of Google search results. That requires a lot of on page and off page SEO. However, avoiding, or finding and fixing, these technical errors will make it much easier for Google to correctly find, crawl and index your pages. Which is the ultimate goal of technical SEO.